Disentangled 3D Scene Generation with Layout Learning
TL;DR: Text-to-3D generation of scenes decomposed automatically into objects, using only a pretrained diffusion model.
TL;DR: Text-to-3D generation of scenes that are decomposed automatically into objects.
Click the numbers to discover different objects!
“a chef
rat on a tiny stool cooking a stew”
“a chicken hunting for
easter eggs”“a
pigeon having some coffee and a bagel, reading the newspaper”“two
dogs in matching outfits padding a kayak”“a
sloth on a beanbag with popcorn and a remote control”“a
bald eagle having a drink and a burger at the park”“a bear
wearing a flannel camping and reading a book by the fire”
draw_abstract
Abstract
We introduce a method to generate 3D scenes that are disentangled into their component objects. This disentanglement is unsupervised, relying only on the knowledge of a large pretrained text-to-image model. Our key insight is that objects can be discovered by finding parts of a 3D scene that, when rearranged spatially, still produce valid configurations of the same scene.
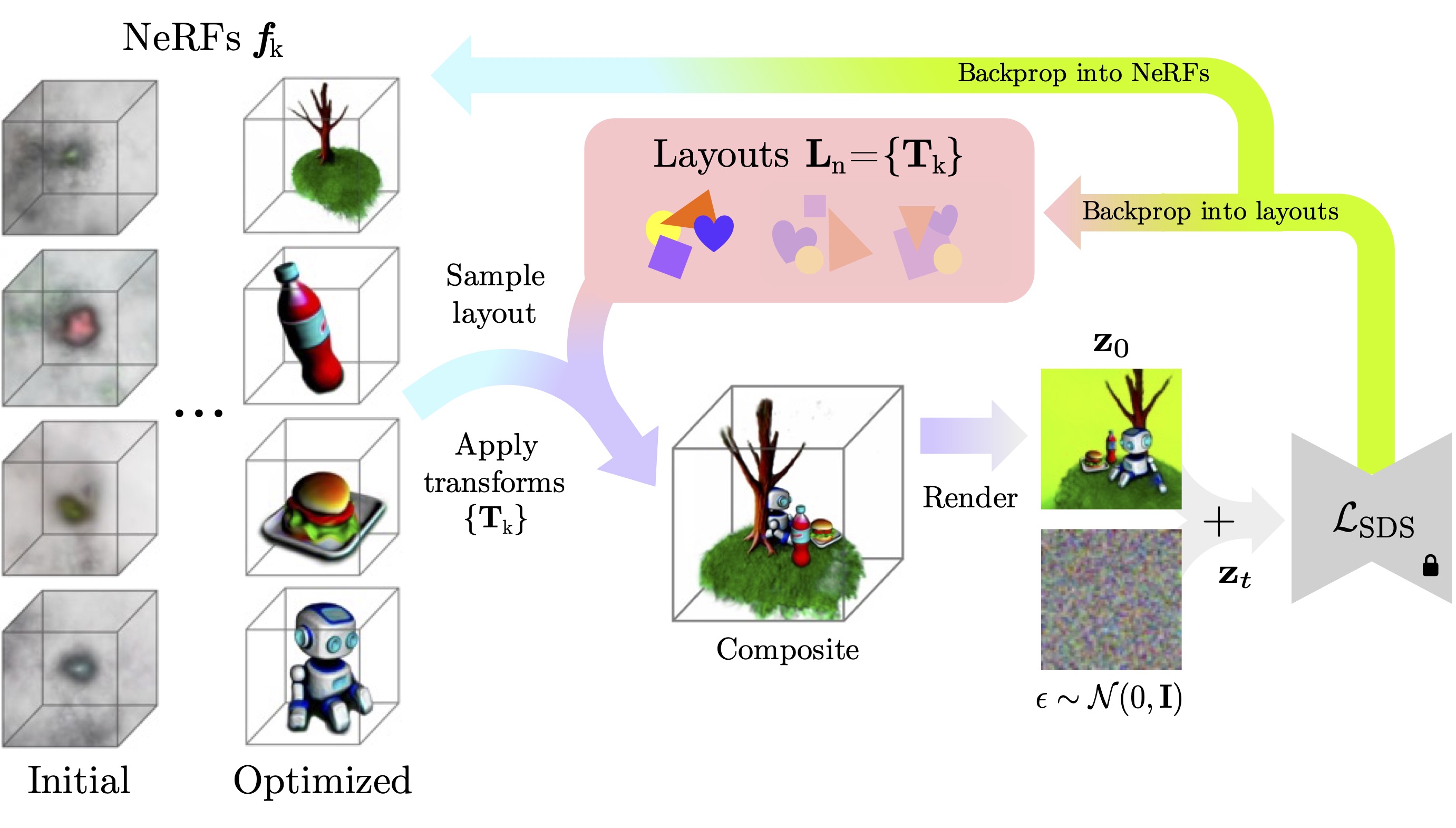
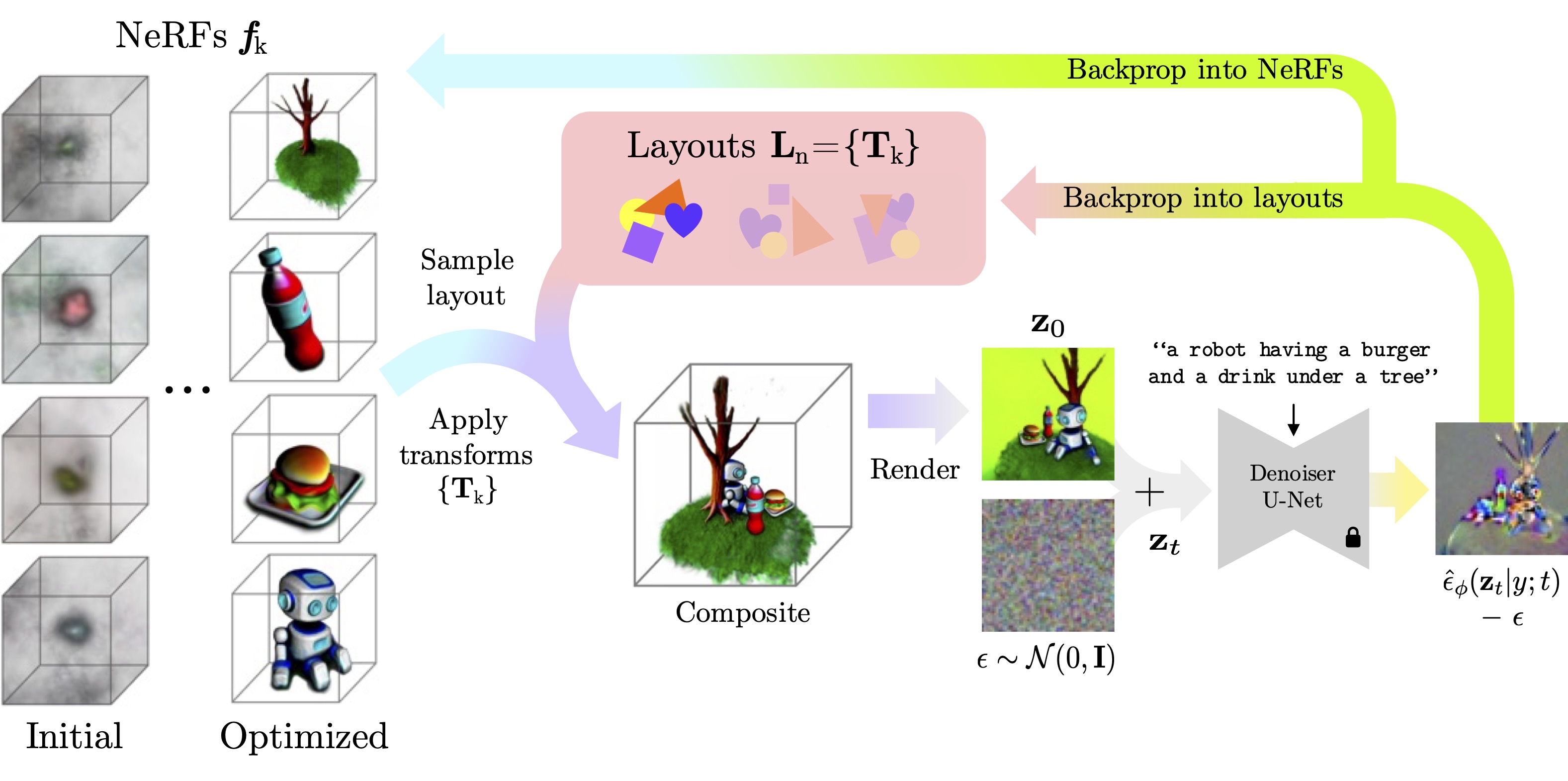
Concretely, our method jointly optimizes multiple NeRFs from scratch – each representing its own object – along with a set of layouts that composite these objects into scenes. We then encourage these composited scenes to be in-distribution according to the image generator. We show that despite its simplicity, our approach successfully generates 3D scenes decomposed into individual objects, enabling new capabilities in text-to-3D content creation.
palette Applications
open_with Building scenes around objects
We can take advantage of our structured representation to learn a scene given a 3D asset in addition to a text prompt, such as a specific cat or motorcycle. By freezing the NeRF weights but not the layout weights, the model learns to arrange the provided asset in the context of the other objects it discovers. We show the entire scenes the model creates along with surface normals and a textureless render.
😾 grumpy cat🏍 sport
motorbike
“a cat wearing a
santa costume holding a present next to a miniature christmas tree”
“a cat wearing a hawaiian shirt and
sunglasses, having a drink on a beach towel” Asset
Asset
open_with Separating a NeRF into objects
Given a NeRF representing a scene and a caption, layout learning is able to
parse the scene into the objects it contains without any per-object supervision. We accomplish this by
requiring renders
of one of the
“a bird having some sushi and
sake”“two cute cats
wearing baseball uniforms playing catch”
open_with Automatically arranging existing objects
Allowing gradients to flow only into layout parameters while freezing a set of provided 3D assets results in reasonable object configurations, such as a chair tucked into a table with spaghetti on it, despite no such guidance being provided in the text conditioning.
🍝 spaghetti / 🪑 chair / 🔴
table🦆 rubber duck
/ 🛁 bathtub / 🚿 shower head
🖥️ monitor
/
⌨️ keyboard / 🖱️ mouse
open_with Sampling different layouts
Our method discovers different
plausible arrangements for objects. Here, we optimize each
example over
“two
flamingos sipping on cocktails in a desert oasis”
“a robe, a
pair of slippers, and a candle”
Analysis
open_with Ablation
We optimize different variants of our model with
“a backpack, water bottle, and
bag of chips”“a slice of
cake, vase of roses, and bottle of wine”
Learn K NeRFs+ learn 1 layout+ learn N layoutsPer-object SDSopen_with Limitations
Layout learning inherits failure modes from SDS, such as the Janus problem. It also may undesirably
group objects that always move together,
such as a horse and its rider, or segment objects in undesired ways, such as breaking off an arm from
the ninja's body. For certain prompts that generate many
small objects, choosing
“some
astronauts forming a human pyramid riding a horse”
“two fancy
llamas enjoying a tea party”
“a ninja
slicing different fruit in mid-air with a katana”
“a monkey
having a whiskey and a cigar, using a typewriter”
format_quote Citation
@misc{epstein2024disentangled,
title={Disentangled 3D Scene Generation with Layout Learning},
author={Dave Epstein and Ben Poole and Ben Mildenhall and Alexei A. Efros and Aleksander Holynski},
year={2024},
eprint={2402.16936},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Acknowledgements
We thank Dor Verbin, Ruiqi Gao, Lucy Chai, and Minyoung Huh for their helpful comments, and Arthur Brussee for help with an NGP implementation. DE was partly supported by the PD Soros Fellowship. DE conducted part of this research at Google, with additional funding from an ONR MURI grant.